XChem Manual for current data processing protocols: XChem_User_Training_DataProcessing_XCE_and_PanDDA_2024
Automated hit identification & model building pipelines
An automated data analysis and model building pipeline for fragment screening experiments is under development at DLS and is now availble for testing, please contact Rowan Walker-Gibbons or Conor Wild if you would like to have your visit data processed in this way or have any questions.
The pipeline launches two hit idenitification pipelines in parallel - PanDDA2 and Pipedream (Global Phasing). Note: if you are an industry user we will not be able to run Pipedream on your data unless you are able to provide a Global Phasing license.
- PanDDA2 is an updated version of PanDDA (PanDDA 2) which has been developed by Conor Wild and differs from PanDDA in two major methodological ways: Firstly, it attempts to identify which sets of datasets should be used to produce a statistical model which has the optimal contrast (to each test dataset individually). This allows it to handle subtle heterogeneity between datasets. Secondly it attempts to autobuild the events returned, and then rank the events based on the quality of the model of the fragment that could be constructed. This allows improved rankings of events. PanDDA2 is distributed on GitHub (https://github.com/ConorFWild/pandda_2_gemmi).
- Pipedream is an automated pipeline that links automated data processing with structure refinement with BUSTER and automated ligand fitting with Rhofit, with subsequent BUSTER post-refinement of the top solution. It works best for high occupancy ligands, whereas the PanDDA methods are designed for identifying weakly bound fragments. Documentation: https://www.globalphasing.com/buster/manual/pipedream/manual/index.html.
Both pipelines produce a final 'best' model that includes the ligand automatically fitted. Your results can be found at:
/dls/labxchem/data/<proposal>/<visit>/processing/auto/analysis
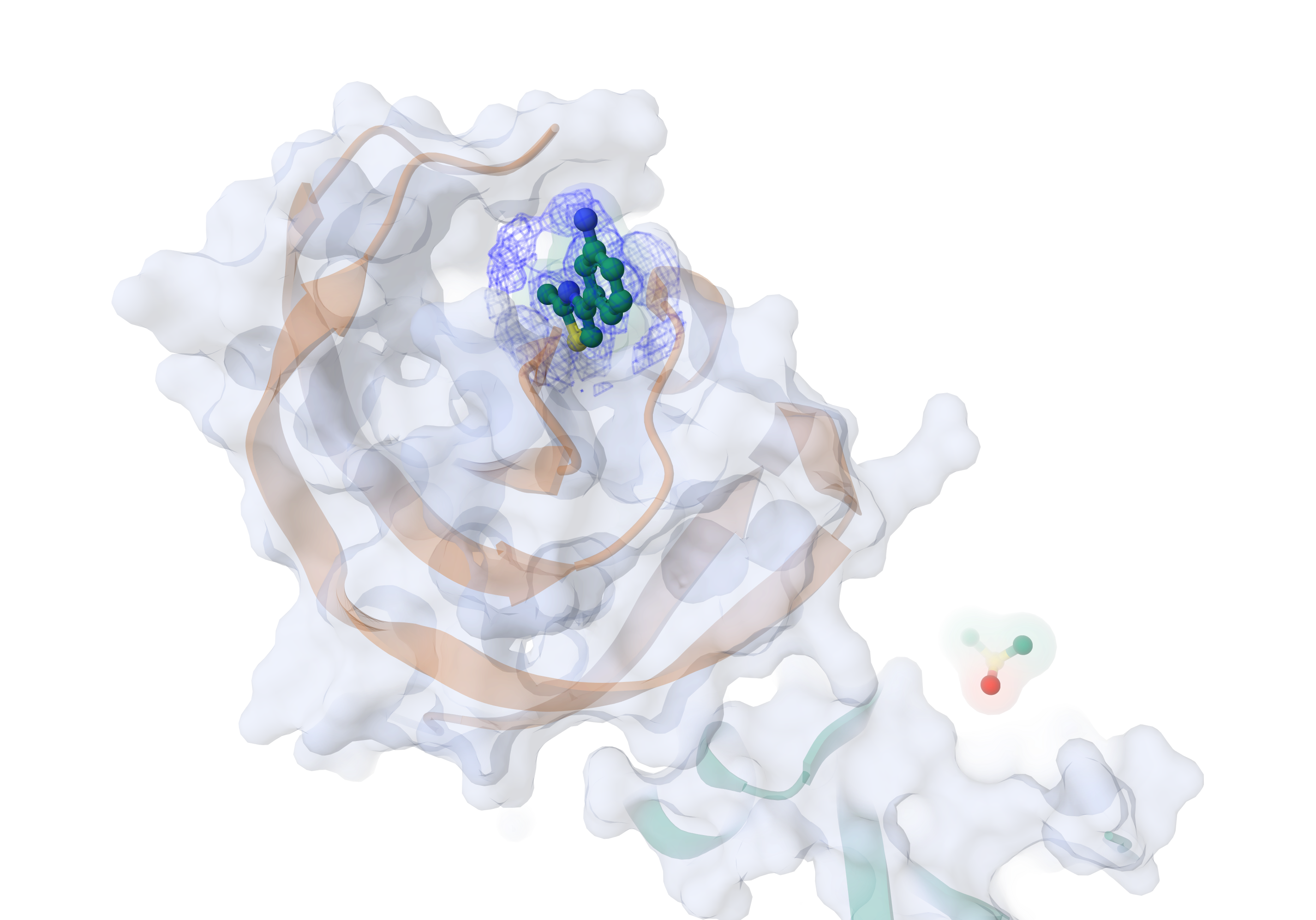
Automated pipeline user guide
Ideally, before your samples go on the beamline for data collection, make sure to upload PDB information for your Protein on ISPyB - this is key if you wish any of the downstream pipelines to trigger. Multiple PDB files can be uploaded for a particular Protein, and Dimple will select the best matching PDB file to use as a reference structure; this is particularly useful for crystal systems that display crystal polymorphism.
The automated hit identification and model building pipelines will trigger downstream from Dimple (CCP4) as data arrives from beamline data collection, once all such jobs have finished processing for a particular crystal. Whilst Pipedream can begin processing right away, PanDDA2 has an additional requirement that a threshold number of comparator datasets must first be collected before processing can begin (default `comparator_threshold = 350`).
Unless specified otherwise, PanDDA2 will run with default settings. However, if you would like specific options applied, you can add these to the `.user.yaml` file in the visit directory, e.g:
autoprocessing:
pandda:
high_res_lower_limit: 2.5
data:
acronym: A71EV2A
Analysis of the auto-pipeline results
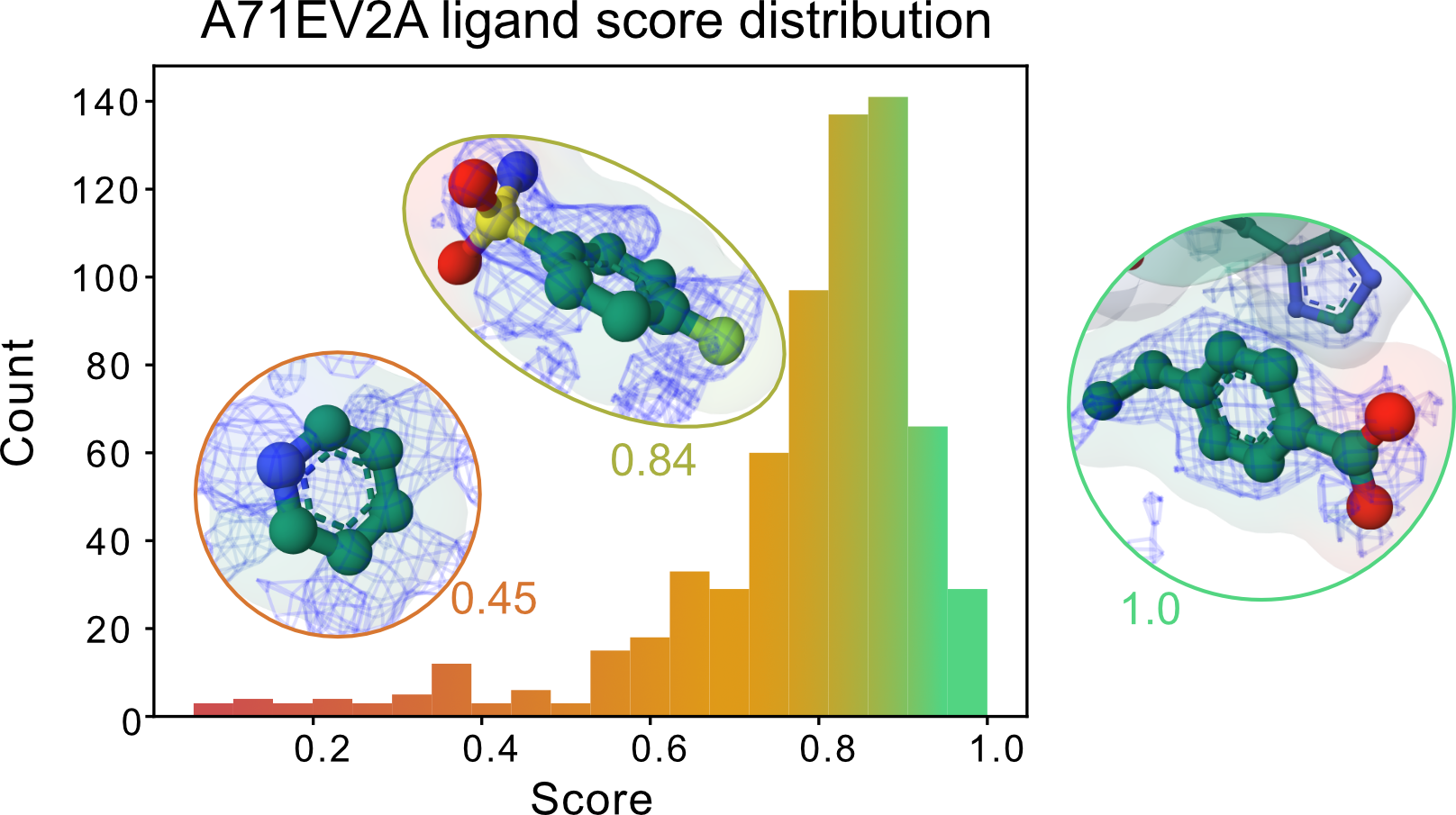
Currently, we advise that the auto PanDDA2 results must be analysed as normal via the `pandda.inspect` tool in XChemExplorer. To aid the analysis of large fragment screens, we have implemented a CNN scoring method to rank the quality of the final autobuilds. Since many aspects of the pipeline such as this are still under development, feedback is always appreciated.
The Pipedream results can be collated as normal (following instructions at https://github.com/Daren-fearon/pipedream_xchem/tree/main) to produce a highly detailed HTML report, with ability to rank ligands and export back to the XChem environment.

Under development
- Automated model completion (water fitting)
- Automated XChemAlign (XCA) & upload of data to Fragalysis

Diamond Light Source is the UK's national synchrotron science facility, located at the Harwell Science and Innovation Campus in Oxfordshire.
Diamond Light Source Ltd
Diamond House
Harwell Science & Innovation Campus
Didcot
Oxfordshire
OX11 0DE
Copyright © Diamond Light Source. Diamond Light Source® and the Diamond logo are registered trademarks of Diamond Light Source Ltd
Registered in England and Wales at Diamond House, Harwell Science and Innovation Campus, Didcot, Oxfordshire, OX11 0DE, United Kingdom. Company number: 4375679. VAT number: 287 461 957. Economic Operators Registration and Identification (EORI) number: GB287461957003.