Immediately Following Data Collection
Click here to find out how data processing is run.
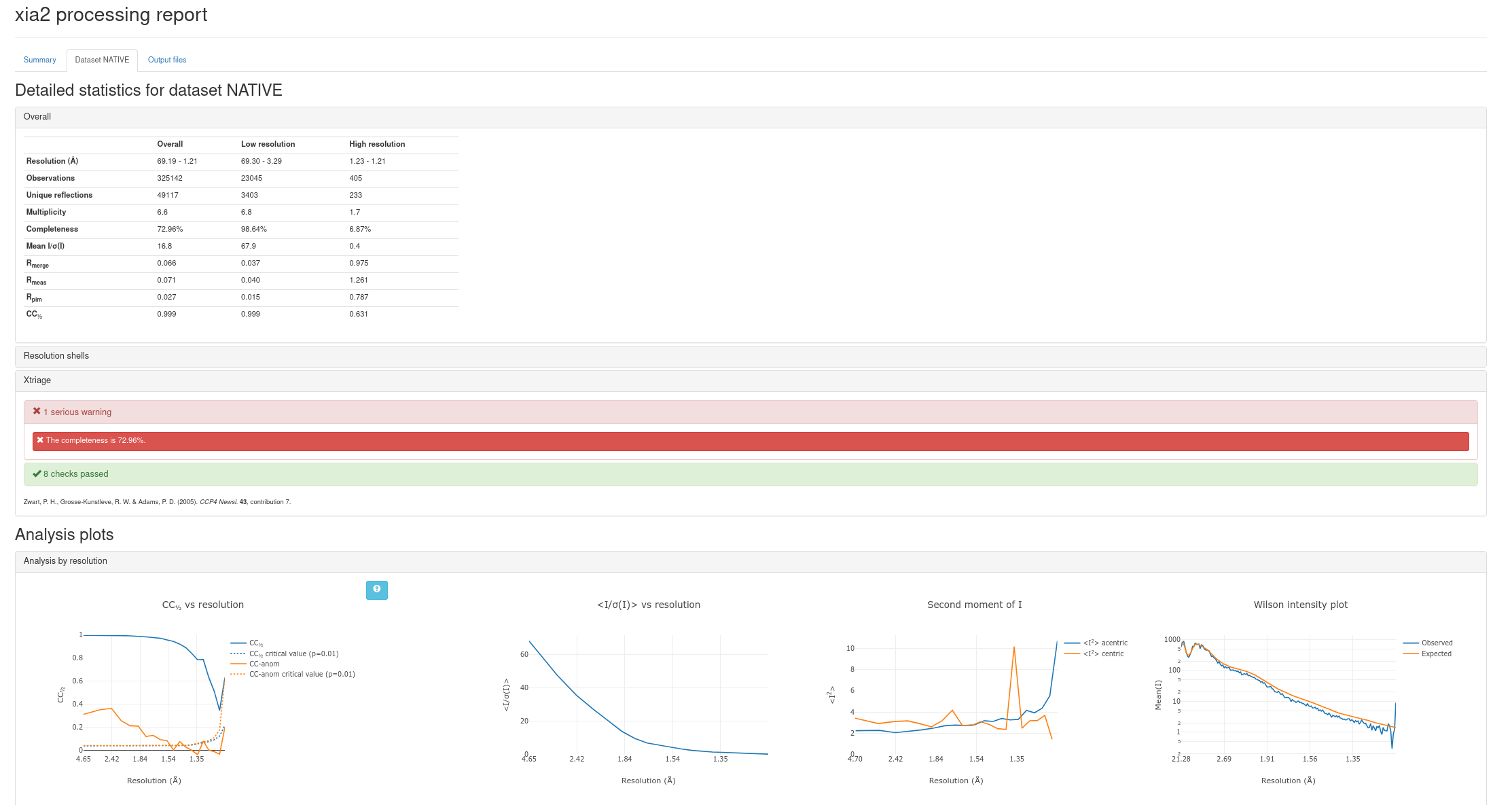
As soon as data collection is complete a second script is started, which stops the per-image analysis service and initiates data processing with fast_dp and xia2. The aim of the data processing with fast_dp is to deliver an indication of the quality of the data and reasonable intensities for subsequent analysis in the shortest possible time. To this end it employs both multi-core and multi-node parallelism on the MX cluster. Typically fast_dp will deliver the results of processing, specifically the scaled and merged intensities and the merging statistics (Table 1) within two minutes of the end of data collection, even for fine sliced Pilatus data. Two xia2 jobs are also started, one using DIALS and one using XDS / XSCALE, with the intention of producing higher quality data for downstream analysis. Each of these xia2 jobs generates a report on the data quality which is linked from the HTML pages (Figure 1). At the end of the fast_dp /xia2 data processing there are a number of downstream analysis steps added, with the intention of giving more focussed experimental feedback.
Table 1 Example results from fast_dp
--------------------------------------------------------------------------------
Low resolution 28.01 28.01 1.51
High resolution 1.47 6.56 1.47
Rmerge 0.050 0.024 0.540
I/sigma 16.80 53.90 2.50
Completeness 94.7 97.8 90.9
Multiplicity 6.9 6.2 6.9
CC 1/2 0.999 0.999 0.911
Anom. Completeness 94.5 93.9 90.6
Anom. Multiplicity 3.5 3.3 3.5
Anom. Correlation 0.350 0.663 0.041
Nrefl 247031 2683 17320
Nunique 35919 435 2521
Mid-slope 1.161
dF/F 0.055
dI/sig(dI) 1.042
--------------------------------------------------------------------------------
Merging point group: C 1 2 1
Unit cell: 53.18 61.26 69.30 90.00 93.05 90.00
Figure 1 HTML reports on data processing generated by xia2